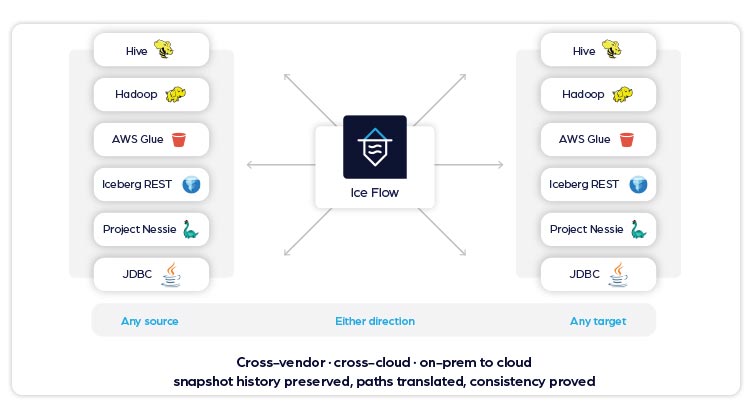
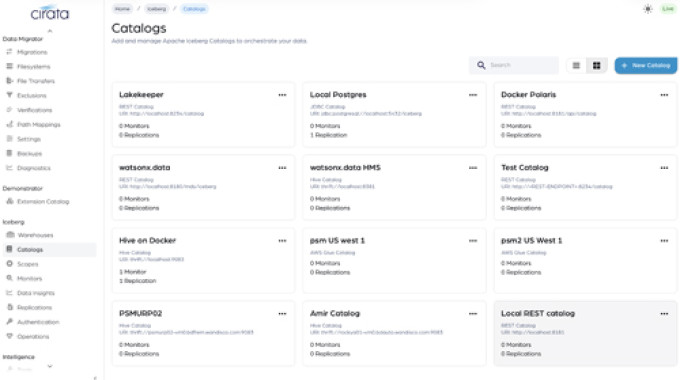
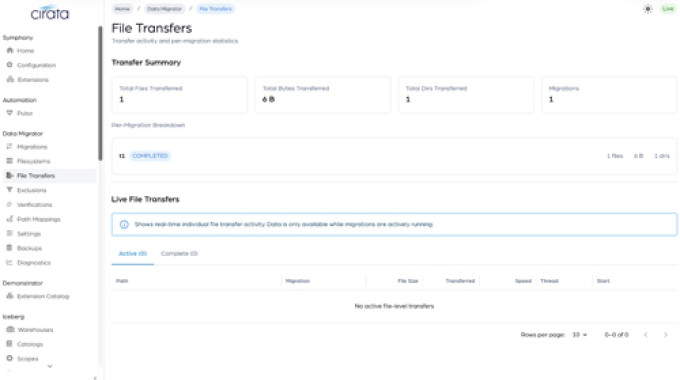
Ice Flow extension
Manage data in Iceberg-native, open standard formats, between any pair of catalogs, across vendors, clouds, and on-premises, without compromise or lock-in.
Built by Cirata
|
Tech Preview