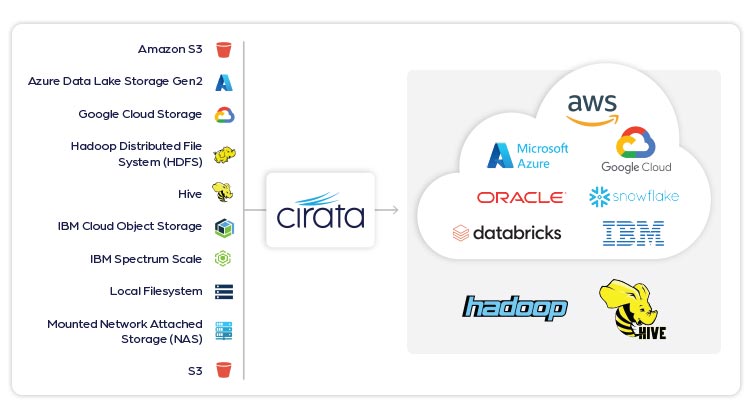
Supported storage
HDFS, Amazon S3, Azure Data Lake Storage Gen2, Google Cloud Storage, Ceph, any S3-compatible storage, source or target
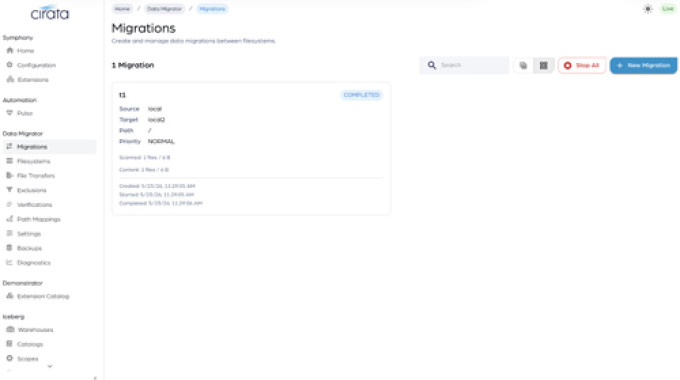
Migration modes
Live continuous (source stays open for application writes) or one-time
Change detection
HDFS inotify, S3 event streams (SQS or Kafka), periodic re-scan fallback
Authentication
S3 access-key, IAM role, AWS profile, STS / IRSA; ADLS Shared Key or Service Principal (OAuth2); per-filesystem Kerberos UGI for HDFS
Path translation
Declarative source-prefix → target-prefix mappings, applied across storage vendors and protocols
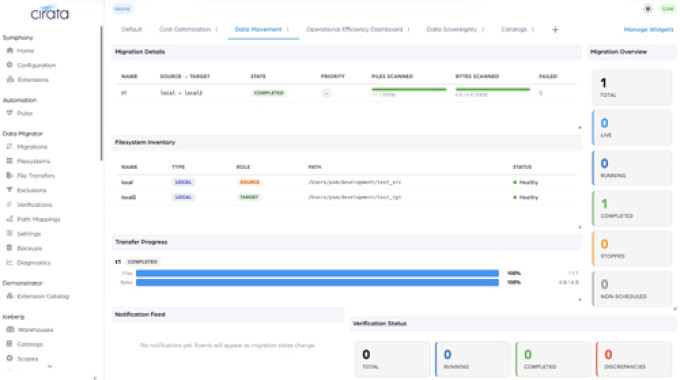
Verification
Per-migration, on-demand or scheduled; pass/fail per file with reason codes; full lifecycle through UI, REST, CLI, and MCP
Deployment
Distributed + hybrid environments, horizontally scalable via Symphony WorkPartitioner
Time-to-value
Minutes to first migration; no agents on source or target, no cluster of your own to operate